
A quick search for the word data on India Water Portal results in a flood of queries - people are looking for water data - for specific villages, cities or for the entire country.
This endless search for data indicates two things: an overwhelming interest - not only from practitioners and experts but even residents as they seek to demystify water and hold this slippery resource within their grasp. But, unfortunately, like groundwater, water data itself has largely remained invisible - stuck in folders and files, which brings us to the second thing- the problem of discoverability.
Let us take the example of any hill state in this country, which is dotted with springs. Much of the lands that the springs flow from are governed by the Forest Department. Communities depending on this water - and indeed even other departments that want to work on providing water to communities (e.g. Public Health Engineering Department or PHED) must all work with the Forest Department to understand the resource and carry out recharge activities to ensure it doesn’t dry up.
Today, this does not happen. This is because, even basic information like the spring’s location remains a mystery and departments remain mired in protocol - often recreating data sets (including geospatial information) every time a new programme on water is commissioned. However, data, much like the springs can be understood and demystified easily. It can escape the confines of files and folders and flow - unconfined, to help people understand and build on each other’s work.
Making data flow: The registry thinking
Can we reimagine the possibility of designing a trusted data store that not only captures water data but also makes it easily accessible for people, organizations and systems to leverage? Can we design capabilities to ingest, protect and use the data in ways that amplify value for its users? Can all of this be scalable yet contextual? A registry is meant to do just this.
A registry is a shared digital infrastructure on which authorized agencies can publish digitally signed (verified) data about their users, entities, or resources (such as water springs). This data set can be granted consented access via open Application Programming Interface (API) for other authorized users or systems to consume.
This digital infrastructure empowers organizations, systems and communities to use the data to resolve their local needs.
Working at scale
Let us apply this thinking to the problem of springs in hilly states. For the sake of simplicity we will consider the following actors - forest department, line departments such as public health and engineering department (PHED) and communities.
Let us examine a few benefits that a spring registry can offer to each of these actors:
Forest Department
- Can maintain a record of the location & discharge of all the springs
- Can be alerted when there is a reduction in discharge, flagging off the need to protect wildlife through other water sources
- Can optimize funds allocation for soil and water conservation.
Line Departments ex. Public Health and Engineering Department (PHED)
- Don’t have to duplicate the effort of recreating existing spring data when working on new projects
- Can quickly build relevant solutions on top of the Forest Spring registry
- Can open up new data sets for more enhanced collaboration
Communities
- Can gain access to local spring’s data (ex. water discharge) in their village.
- Can improve community decision making - decide how best to use the water, which springs to recharge etc.
- Can submit accurate village level micro-plans for funding.
The below diagram depicts the flow of data from the originator (forest department) into the registry and then to various consumers such as PHED, communities etc.
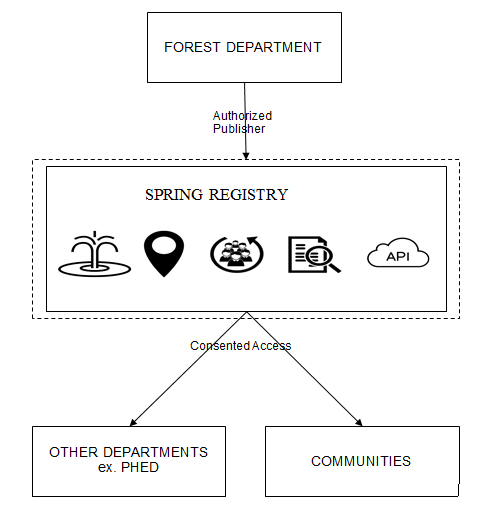
Creating such systems requires us to understand and design for appropriate ingestion, protection and usage of data. Following are few key considerations:
Ingestion
- Is the data created/curated by your organization, your partners or through the extended ecosystem?
- Is the data time sensitive?
- Can you trust the quality and accuracy of the data? If not, how do you ensure that it is clean when ingested?
- Does the data require an independent entity to certify its authenticity?
Protection
- Which data attributes require encryption and protection when stored?
- Which data attributes require explicit consent to use?
- Who are the actors leveraging the data? What attributes of the data do they need access to?
Usage
- Who are the users of the data?
- What data is being read?
- How and where is the data being used?
Operationalizing a registry
Let’s look at some answers using the spring example itself. When setting up a springs registry, we would need to decide who all collect data, whether there can be a mechanism to verify if they have the expertise to carry out data collection (e.g. did they receive training in discharge measurement), if we need a maker-checker method to moderate/ verify data upload and who consumes what data - with different views for different people that takes into account data protection laws.
By doing this, we not only make a scarce resource (data) abundant but also create the ability for each of the actors who interact with the spring to become problem solvers. Thus building on a common database and helping distribute the ability for the ecosystem to solve.
Having said that, the true value of a registry is realized only when the quality of data that it holds is accurate, consistent and timely. This requires that there is a custodian of the registry who is aware of the origin (provenance) of the data, can legally host, manage, maintain and protect it for security and privacy.
The first instances of the registry thinking can be traced back to paper record keeping, especially in health care. With the advent of technology, several of these paper records have moved online. However, while this increases accessibility, it is still extremely hard to share and use the data at scale.
The intent of future registries should be to address these challenges by providing open APIs through which digitally signed data can be accessed. It should provide the ability to easily search and discover relevant and contextual information and importantly be available in machine readable format for external systems to access. OpenSABER is one such open-source software that organizations can leverage to build and deploy highly scalable and trusted registries.
The water ecosystem has made several strides forward in ensuring more rigorous data collection and use in decision making. By using the registry thinking we can ensure that this data is liberated from the custody of one set of users and a single programme making it a reusable asset that each programme and actor builds on.
Anand Rajan is a platform advisor who works on amplifying network interactions by designing solutions that fit ecosystem needs, scaled through responsive digital infrastructure.